This diagram explains the flow when a user attempts to access an on-prem application that uses IWA.
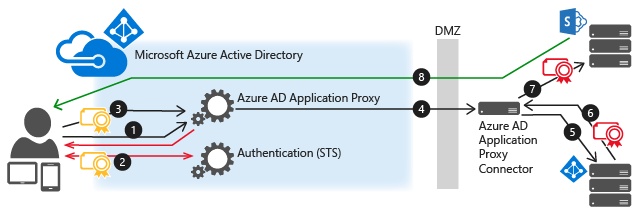
- The user enters the URL to access the on-prem application through Application Proxy.
- Application Proxy redirects the request to Azure AD authentication services to preauthenticate. At this point, Azure AD applies any applicable authentication and authorization policies, such as multifactor authentication. If the user is validated, Azure AD creates a token and sends it to the user.
- The user passes the token to Application Proxy.
- Application Proxy validates the token and retrieves the User Principal Name (UPN) from it, and then sends the request, the UPN, and the Service Principal Name (SPN) to the Connector through a dually authenticated secure channel.
- The Connector performs Kerberos Constrained Delegation (KCD) negotiation with the on-prem AD, impersonating the user to get a Kerberos token to the application.
- Active Directory sends the Kerberos token for the application to the Connector.
- The Connector sends the original request to the application server, using the Kerberos token it received from AD.
- The application sends the response to the Connector, which is then returned to the Application Proxy service and finally to the user.
Comments