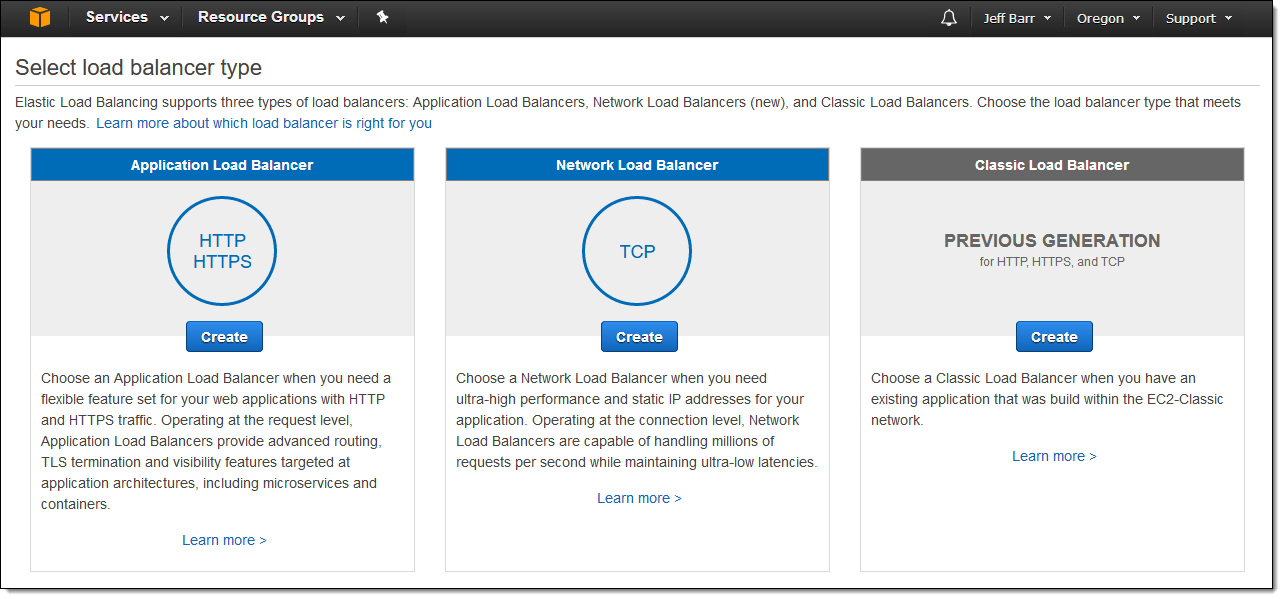
AWS announced Network Load Balancer for the Elastic Load Balancing service designed to handle millions of requests per second while maintaining ultra-low latencies. This new load balancer is optimized to handle volatile traffic patterns while using a single static IP address per Availability Zone.
Static IP Addresses – Each Network Load Balancer provides a single IP address for each VPC subnet in its purview. If you have targets in a subnet in us-west-2a and other targets in a subnet in us-west-2c, NLB will create and manage two IP addresses (one per subnet); connections to that IP address will spread traffic across the instances in the subnet. You can also specify an existing Elastic IP for each subnet for even greater control. With full control over your IP addresses, Network Load Balancer can be used in situations where IP addresses need to be hard-coded into DNS records, customer firewall rules, and so forth.
Comments