Bernoulli Distribution:
Definition: The Bernoulli Distribution is a discrete probability distribution that models a random experiment with two possible outcomes - success (usually denoted as 1) and failure (usually denoted as 0). It is named after Swiss mathematician Jacob Bernoulli.
Probability Mass Function (PMF): The PMF of the Bernoulli Distribution is defined as:
Mean and Variance: The mean (expected value) of the Bernoulli Distribution is , and the variance is .
Mean
The expected value of a Bernoulli random variable is
This is due to the fact that for a Bernoulli distributed random variable with and we find
Variance
The variance of a Bernoulli distributed is
We first find
From this follows
With this result it is easy to prove that, for any Bernoulli distribution, its variance will have a value inside .
Graphical Representation:
Here's a bar graph illustrating the Bernoulli Distribution for different values of :
Bernoulli distribution Probability mass function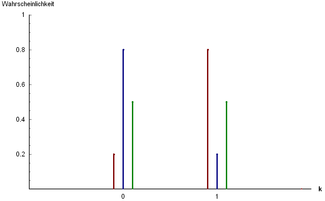
Three examples of Bernoulli distribution:
andandandIn this graph, you can see that the probability of success () is represented by the height of the bar at , and the probability of failure () is represented by the height of the bar at . Since it's a discrete distribution, there are only two possible outcomes.
Parameters Support PMF CDF Mean Median Mode Variance MAD Skewness Ex. kurtosis Entropy MGF CF PGF Fisher information Use Cases:
- The Bernoulli Distribution is commonly used to model random experiments with binary outcomes, such as:
- Coin flips (success = heads, failure = tails).
- Pass/fail experiments (success = pass, failure = fail).
- Click-through rate (success = click, failure = no click).
It serves as the building block for other important distributions like the Binomial Distribution and the Geometric Distribution.
- The Bernoulli Distribution is commonly used to model random experiments with binary outcomes, such as:


![{\displaystyle \operatorname {E} [X]=p}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0eb41a45634ab84b13b83cb1488b626aa2129285)


![{\displaystyle \operatorname {E} [X]=\Pr(X=1)\cdot 1+\Pr(X=0)\cdot 0=p\cdot 1+q\cdot 0=p.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5011326253761bfe33bc3d51773a83268b8a56b7)
![\operatorname {Var} [X]=pq=p(1-p)](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d4e26d8a1fdfb90e91a2fafd5fb3841de88f1fb)
![{\displaystyle \operatorname {E} [X^{2}]=\Pr(X=1)\cdot 1^{2}+\Pr(X=0)\cdot 0^{2}=p\cdot 1^{2}+q\cdot 0^{2}=p=\operatorname {E} [X]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1bf32718a7a52087297a46d9ebc177ee0c80df07)
![{\displaystyle \operatorname {Var} [X]=\operatorname {E} [X^{2}]-\operatorname {E} [X]^{2}=\operatorname {E} [X]-\operatorname {E} [X]^{2}=p-p^{2}=p(1-p)=pq}](https://wikimedia.org/api/rest_v1/media/math/render/svg/41972e4aade1430eb47d46a91051f00a583e0c45)
![{\displaystyle [0,1/4]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/604604d2122dc1c25141a841483b889d6832f261)












![{\displaystyle {\begin{cases}0&{\text{if }}p<1/2\\\left[0,1\right]&{\text{if }}p=1/2\\1&{\text{if }}p>1/2\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/482cc0f5f8c739e3fe2462d72ee5b9f1f7b5d5a4)










This distribution is fundamental in probability theory and statistics, especially when dealing with events that have only two possible outcomes.
Comments